ViExam: Are Vision Language Models Better than Humans on Vietnamese Multimodal Exam Questions?

*Equal contribution
We evaluate VLMs on Vietnamese multimodal exam questions and find they significantly underperform humans (57.74% vs. 66.54% average accuracy). We introduce ViExam, the first comprehensive Vietnamese multimodal benchmark with 2,548 genuinely visual questions across 7 academic domains.
Vietnamese high school students regularly face complex diagram-based questions in their graduation exams, from physics problems involving electrical circuits and mechanical waves, function tables and diagrams in mathematics, to chemistry questions with molecular structures and Vietnamese explanations. How do SOTA VLMs handle these problems?
Vision Language Models (VLMs) have achieved remarkable success on English benchmarks, but their ability to handle real-world educational content in Vietnamese remains largely unknown. In this work, we introduce the ViExam (VLMs), benchmark to test VLM performance on Vietnamese educational assessments, investigating whether VLMs trained predominantly on English data can handle real-world cross lingual multimodal reasoning.
This benchmark contains 2,548 Vietnamese multiple-choice questions spanning seven domains, from mathematics and physics to driving tests and IQ assessments. Each question requires models to simultaneously understand Vietnamese text and interpret visual content, combining information from both text and images to reason and select the correct answer. Additionally, we experiment with various approaches to improve VLM performance on ViExam and provide conclusions for each method.
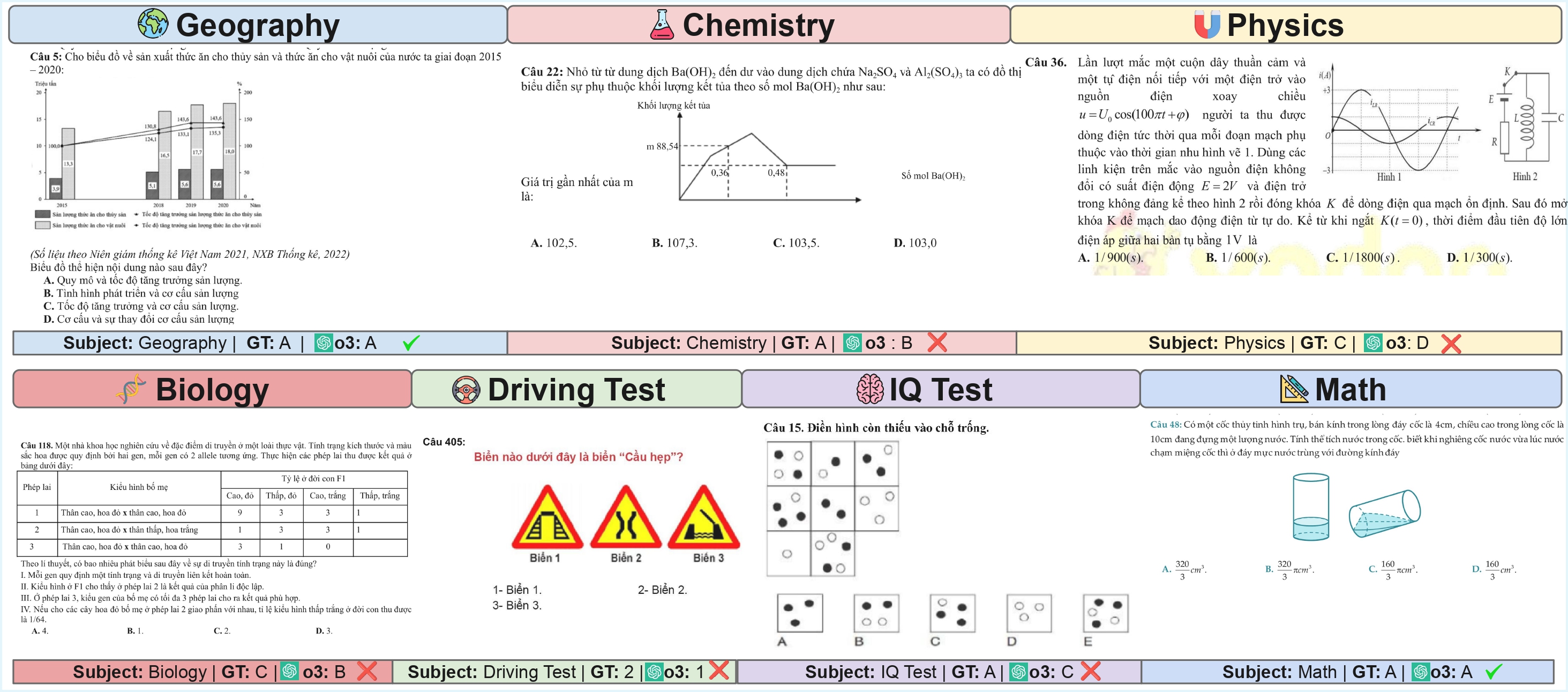
Example of a Vietnamese multimodal exam question from ViExam, combining text and visual elements.
All SOTA VLMs achieve strong OCR performance on Vietnamese text (6% CER and 9% WER), confirming that poor performance on ViExam stems from multimodal reasoning challenges, not basic text recognition failures.
SOTA VLMs achieve only 57% mean accuracy across 7 domains, with Geography being the most accessible (72%) and Physics the most challenging (44%).
The thinking VLM 03 substantially outperforms non-thinking VLMs (74% vs. 48-59%), suggesting that explicit reasoning is crucial for these tasks.
VLMs exhibit a significant bias toward option B (31%) in incorrect answers, suggesting failures may be partially due to biases in training data, not just reasoning limitations.
VLMs perform better on text-only questions (70%) compared to multimodal questions (61%), confirming that integrating visual and textual information is a fundamental challenge.
Open-source VLMs (27.7%) perform substantially worse than closed-source SOTA VLMs (57%), highlighting a significant challenge for publicly available models in understanding Vietnamese multimodal content.
English prompting improves open-source VLMs (+2.9%) but hurts SOTA VLMs (-1.0%), indicating that language-content mismatches affect different types of models in different ways.
To ensure the quality and validity of our benchmark, we developed a systematic 3-stage pipeline to collect, filter, and classify exam questions. This process was crucial for building a dataset that genuinely tests multimodal reasoning, moving beyond simple text-only questions found in previous benchmarks.
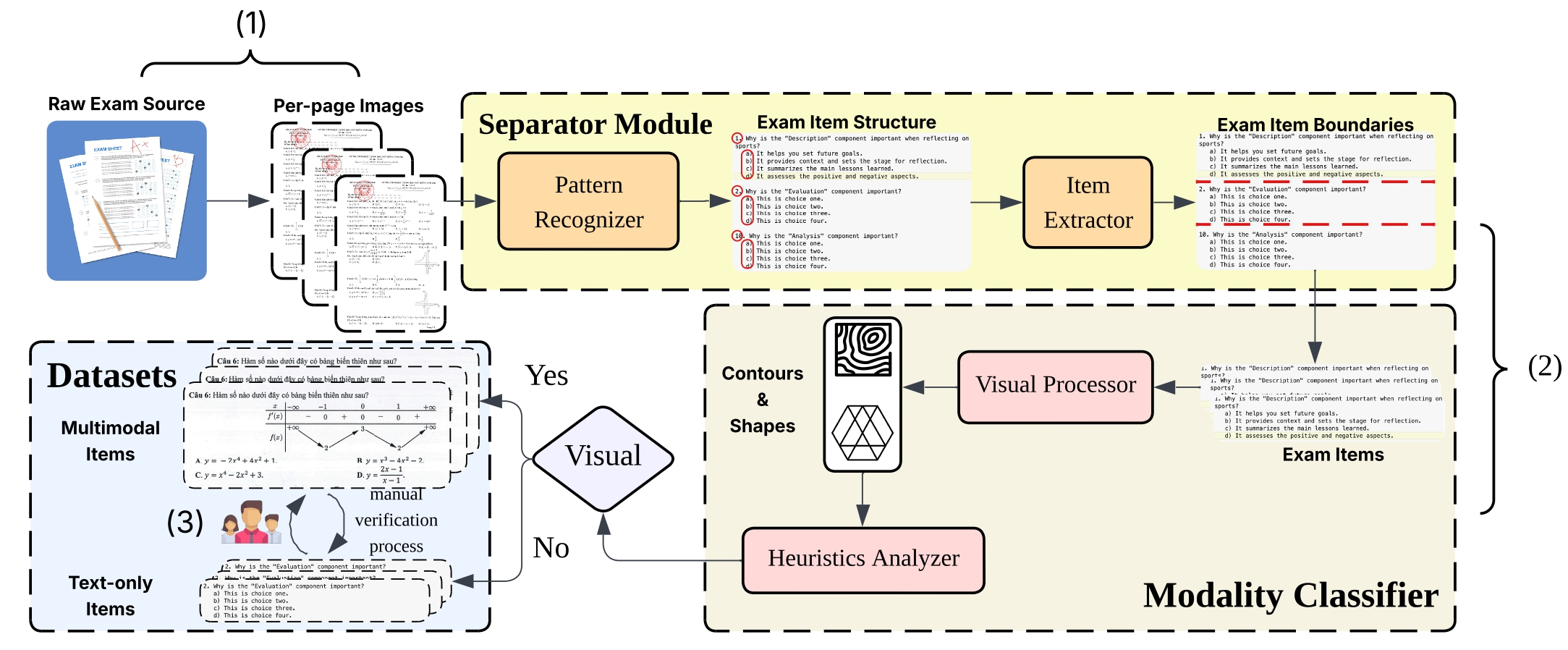
Stage 1: Data Sourcing & Conversion. We began by automatically crawling thousands of exam papers from popular Vietnamese educational websites. Each paper was then converted into high-resolution images, preparing them for analysis.
Stage 2: Automated Classification. Next, our custom pipeline used OCR to identify individual questions on each page. A specialized analyzer then scanned the content of each question, automatically distinguishing multimodal (image-based) questions from text-only ones.
Stage 3: Human Verification. Finally, to ensure maximum accuracy, every single question was manually reviewed by a team of native Vietnamese speakers. They used a custom-built tool to correct any classification errors and validate the final dataset.
Our ViExam benchmark features 2,548 questions across 7 diverse domains.
456 Questions
361 Questions
302 Questions
341 Questions
481 Questions
367 Questions
240 Questions
| Model | a. Math | b. Physics | c. Chemistry | d. Biology | e. Geography | f. Driving | g. IQ | Mean |
|---|---|---|---|---|---|---|---|---|
| Human (Average) | 64.50 | 66.70 | 66.80 | 62.80 | 71.90 | – | – | 66.54 |
| Human (Best) | 98.00 | 100.0 | 100.0 | 100.0 | 100.0 | – | – | 99.60 |
| Open-source VLMs | ||||||||
| Aya Vision 8B | 5.92 | 2.77 | 2.98 | 2.93 | 2.29 | 26.98 | 12.08 | 7.99 |
| Aya Vision 32B | 7.46 | 8.86 | 12.91 | 17.01 | 18.71 | 32.97 | 23.75 | 17.38 |
| Mistral Small 3.2 24B | 20.83 | 12.50 | 20.86 | 27.86 | 27.86 | 39.51 | 30.42 | 25.69 |
| Mistral Medium 3 | 25.88 | 9.42 | 20.53 | 26.98 | 31.19 | 46.32 | 31.25 | 27.37 |
| Llama 4 Scout | 33.55 | 11.91 | 23.51 | 31.09 | 52.18 | 49.86 | 33.75 | 33.69 |
| Llama 4 Maverick | 27.41 | 9.42 | 18.87 | 21.41 | 39.50 | 51.77 | 24.17 | 27.51 |
| Gemma 3 4B | 27.41 | 17.73 | 21.19 | 21.99 | 27.23 | 40.33 | 21.67 | 25.37 |
| Gemma 3 27B | 39.69 | 29.64 | 38.41 | 30.21 | 47.61 | 43.87 | 35.42 | 37.83 |
| Qwen 2.5 VL 32B | 26.75 | 10.56 | 17.88 | 32.26 | 51.35 | 54.50 | 33.33 | 32.38 |
| Qwen 2.5 VL 72B | 37.94 | 19.39 | 40.40 | 37.83 | 60.08 | 54.22 | 42.50 | 41.77 |
| Mean | 25.29 | 13.22 | 21.75 | 24.96 | 35.80 | 44.03 | 28.83 | 27.70 |
| Closed-source/SOTA VLMs | ||||||||
| Gemini 2.5 Flash | 48.46 | 37.12 | 68.54 | 61.29 | 85.03 | 71.12 | 47.50 | 59.87 |
| Sonnet 4.0 | 50.66 | 38.50 | 53.31 | 44.87 | 48.44 | 58.04 | 44.17 | 48.28 |
| GPT 4.1 | 41.01 | 33.80 | 41.72 | 43.70 | 68.81 | 66.21 | 45.83 | 48.73 |
| o3 | 85.09 | 68.98 | 82.78 | 67.16 | 88.98 | 74.66 | 50.83 | 74.07 |
| Mean | 56.30 | 44.60 | 61.59 | 54.26 | 72.81 | 67.51 | 47.08 | 57.74 |
This study documents systematic challenges in VLMs' Vietnamese multimodal reasoning through comprehensive evaluation across 7 academic domains, demonstrating that failures stem from multimodal integration rather than basic text recognition limitations.
SOTA VLMs achieved only 57.74% accuracy on Vietnamese multimodal exam questions while open-source models averaged 27.70%, both underperforming average human test-takers (66.54%).
VLMs consistently struggle with Vietnamese multimodal content integration, with thinking models like o3 substantially outperforming non-thinking models (74.07% vs 48.28-59.87%), suggesting that future work on tool-augmented reasoning is needed to close this gap and achieve better performance on complex reasoning tasks